

GLM-4.5 and GLM-4.5-Air: Next-Generation Unified Reasoning, Coding, and Agentic AI Models
The GLM-4.5 series represents a significant leap in large language model innovation, engineered to unify reasoning, coding, and agentic capabilities within a single architecture. With two flagship models GLM-4.5 and GLM-4.5-Air this release delivers state-of-the-art performance, scalability, and versatility for advanced AI applications.
GLM-4.5 uses 355B total parameters (32B active), while GLM-4.5-Air uses 106B total parameters (12B active). Both offer a hybrid approach with a thinking mode for complex multi-step reasoning and a non-thinking mode for instant responses.
Key Specifications at a Glance
| Model | Total Parameters | Active Parameters | Context Length | Notable Features |
|---|---|---|---|---|
| GLM-4.5 | 355B | 32B | 128K | Hybrid reasoning, native function calling, advanced tool-use |
| GLM-4.5-Air | 106B | 12B | 128K | Lightweight, optimized efficiency, strong reasoning and coding |
Benchmark Performance Overview
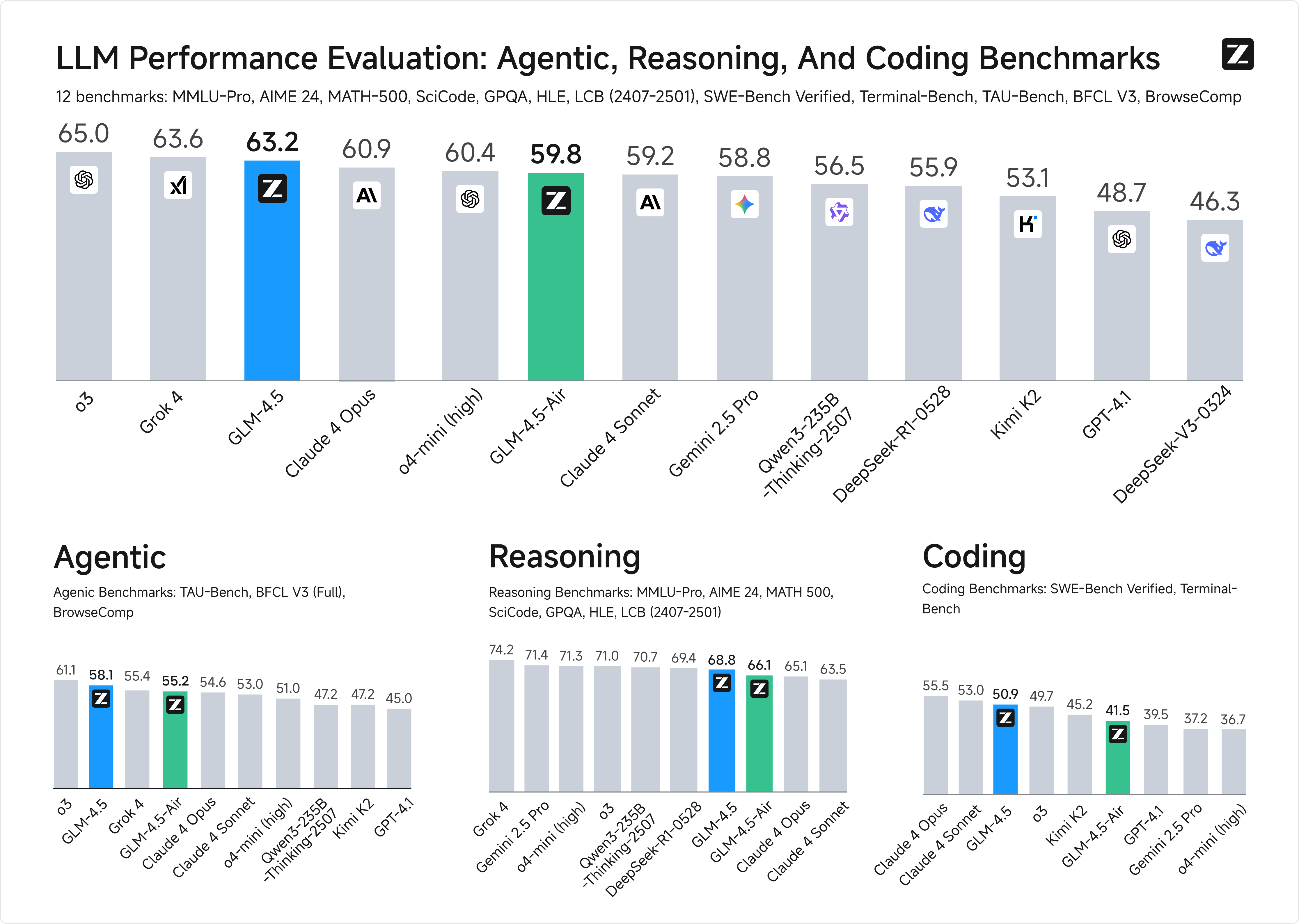
GLM-4.5 and GLM-4.5-Air were evaluated across 12 benchmarks spanning agentic tasks, reasoning, and coding.
Overall Ranking
- GLM-4.5: 3rd globally
- GLM-4.5-Air: 6th globally
Agentic Task Mastery
With a 128K context length and native function calling, GLM-4.5 leads multi-turn, tool-augmented workflows.
- τ-bench (Retail): 79.7%
- BFCL-v3: 77.8% function-calling success
- BrowseComp: 26.4% accuracy, ahead of popular alternatives
Reasoning Excellence
The thinking mode enables deep, multi-step reasoning in mathematics, science, and logic with strong generalization across domains.
- MMLU Pro: 84.6%
- AIME24: 91.0%
- MATH 500: 98.2%
- GPQA: 79.1%
Coding Superiority
GLM-4.5 supports full-stack development and integrates seamlessly with coding agents (e.g., Claude Code, CodeGeex).
- SWE-bench Verified: 164.2
- Terminal-Bench: 237.5
- Tool-calling success rate: 90.6% (best-in-class)
Capabilities span frontend, backend, database, deployment, and high-quality UI/UX generation aligned with human design preferences.
Artifact Creation and Autonomous Development
Beyond text and code, the model produces standalone artifacts:
- Interactive HTML5 mini-games
- SVG visualizations
- Physics simulations
- Slide decks and posters with autonomous asset sourcing
Architecture and Training Innovations
Mixture-of-Experts (MoE) Optimization
- Loss-free balance routing with sigmoid gating
- Deeper layer count for improved reasoning
- Grouped-Query Attention with partial RoPE
- 96 attention heads for benchmark gains
Training Process
- Pre-training: 15T tokens (general) + 7T tokens (code & reasoning)
- Domain-specific fine-tuning: Targeted datasets for priority domains
- MTP layer: Multi-Token Prediction for speculative decoding
Reinforcement Learning with slime
The open-source RL stack slime accelerates agentic training for large models via flexible, high-throughput infrastructure.
- Hybrid synchronous/asynchronous architecture
- Decoupled rollout and training engines
- Mixed-precision acceleration (FP8 rollout, BF16 training)
Post-Training for Agentic Capabilities
Specialized RL refines:
- Agentic coding
- Deep web search
- General tool-use proficiency
A difficulty-based curriculum within extended contexts yields stable, high-performing policies.
Deployment and Accessibility
- Z.ai platform: Direct interaction with artifacts, slides, and full-stack workflows
- Z.ai API: OpenAI-compatible endpoints for GLM-4.5 and GLM-4.5-Air
- Local: HuggingFace and ModelScope with vLLM and SGLang support
Conclusion
GLM-4.5 and GLM-4.5-Air redefine unified AI with cutting-edge reasoning, robust coding performance, and best-in-class agentic workflows powered by an optimized MoE architecture, extensive pre-training, specialized RL, and flexible deployment options.








{kind=link}
0 Comments